A collection of machine learning projects showcasing various algorithms, techniques, and real-world applications across computer vision, regression, and classification tasks.
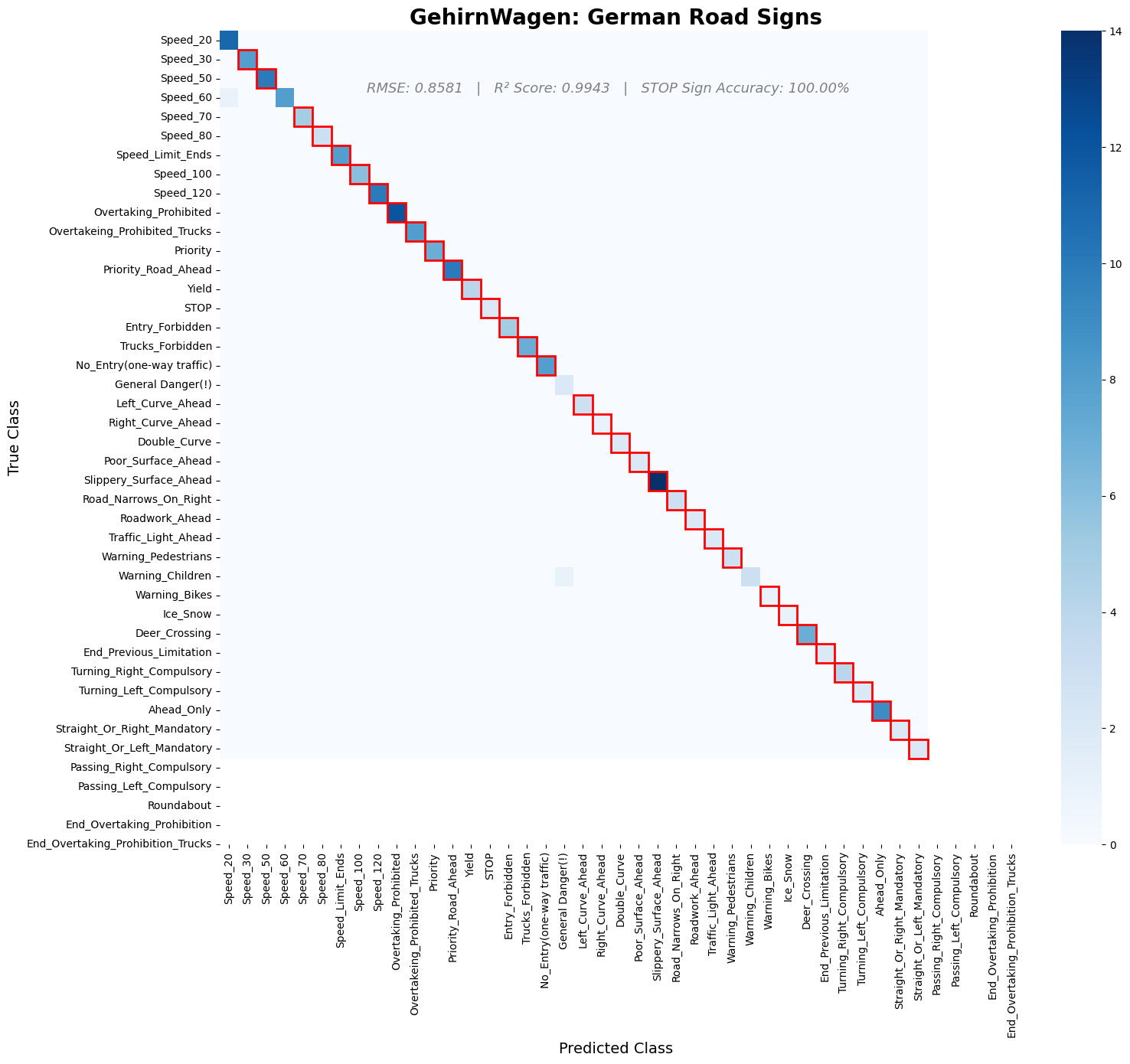
Created a custom convolutional neural network to classify 43 classes of German traffic signs for a fictional self-driving car case study, GehirnWagen. Using transfer learning and custom architecture, the model achieved strong generalization on unseen data and perfect classification of STOP signs — a critical safety metric. This project simulates real-world constraints in autonomous driving perception.

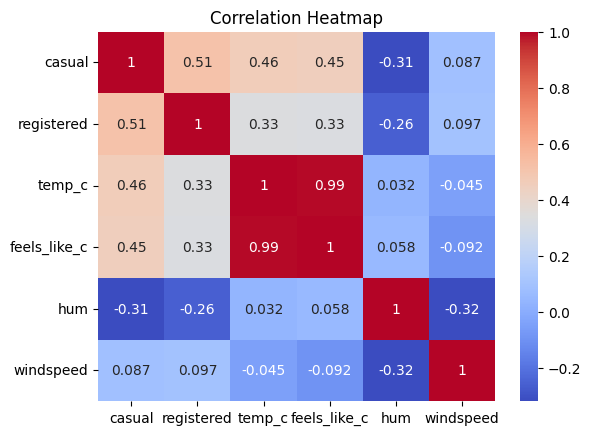
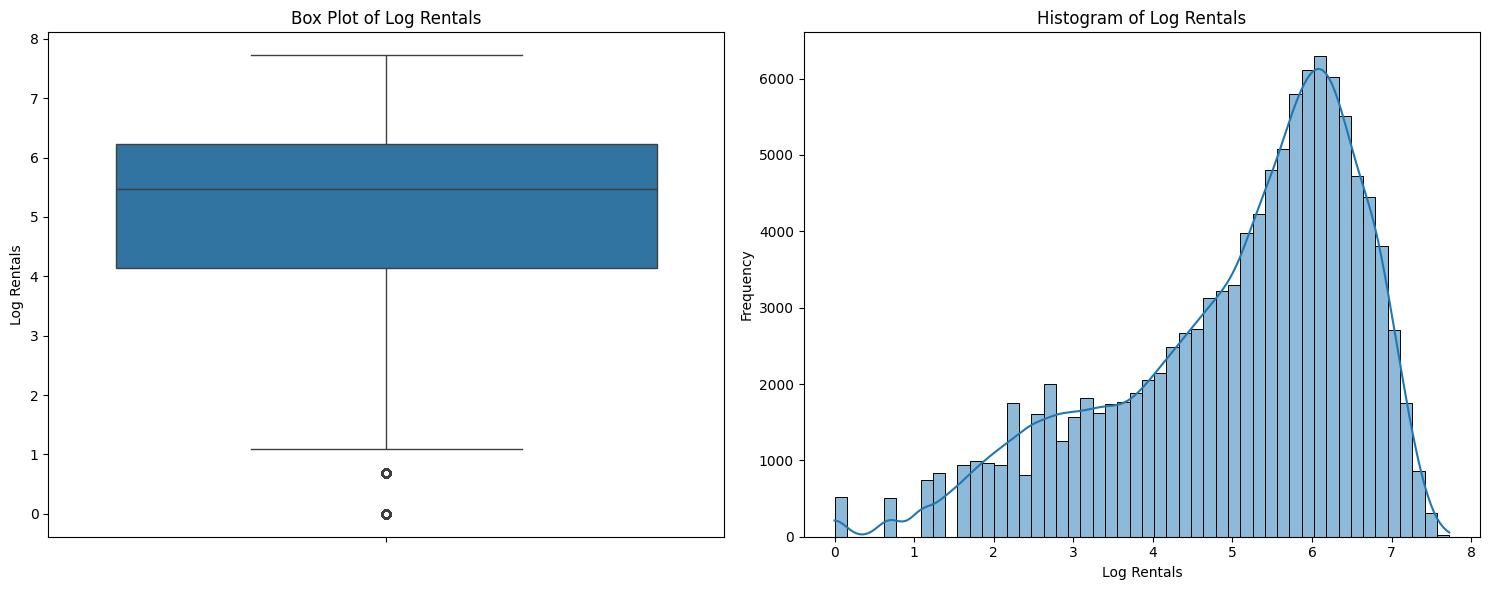
Trained and optimized a neural network to predict hourly bike rental demand in Washington D.C. using the Capital Bikeshare dataset. Extensive feature engineering accounted for COVID-19 lockdown periods, weather, seasonality, and commute hours. The model was evaluated using time-aware train/test splits and tuned with early stopping and dropout regularization.
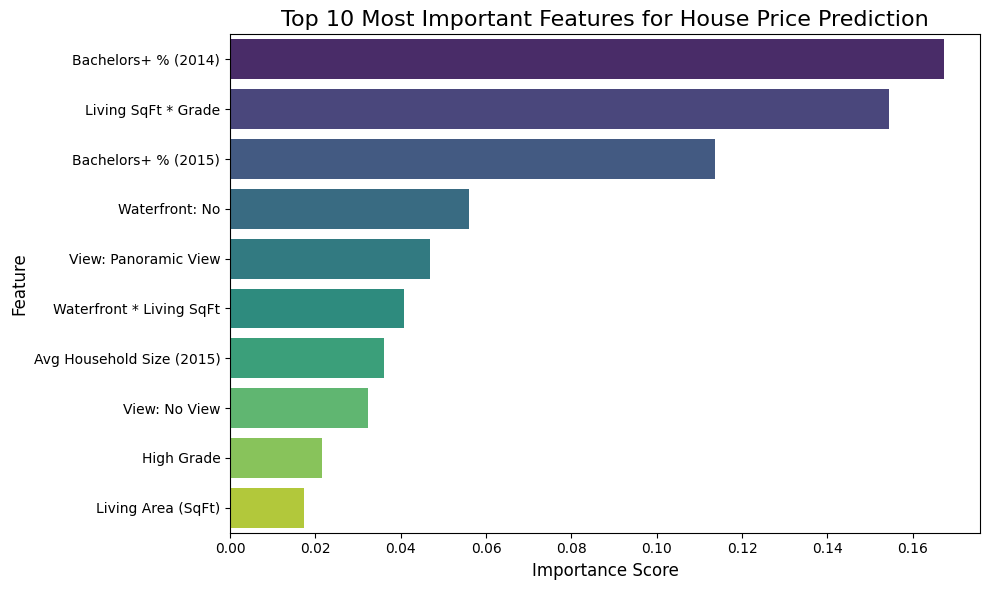
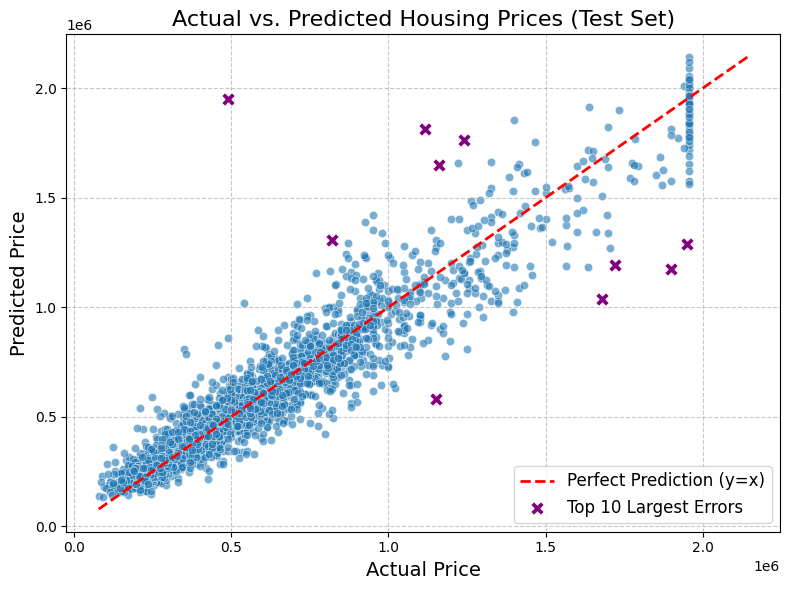
Built an XGBoost regression model to predict housing prices in King County using property features and enriched U.S. Census data. The pipeline included outlier mitigation, engineered interaction terms (e.g., living area × grade), and economic indicators such as income, education, and housing statistics.
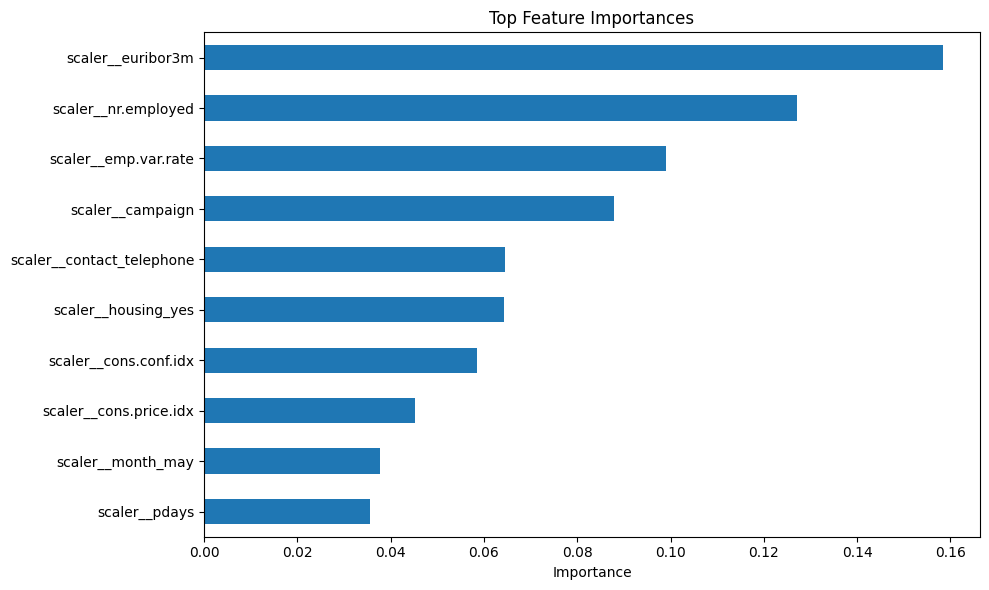
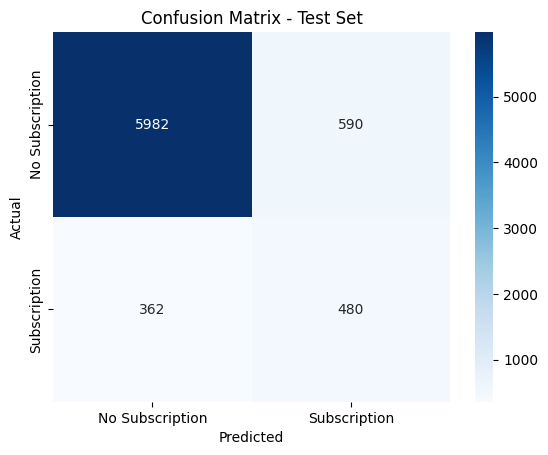
Analyzed bank marketing campaign data to predict customer subscription to term deposits. The project involved classification modeling to identify factors that influence customer decisions and optimize marketing strategies. Used various machine learning algorithms to achieve high prediction accuracy and provide actionable business insights.